
|

|

|

|

|

|

|
|
| DataNucleus AccessPlatform 4.1 Documentation |
|
|
|
|
|
|
|
|
|
|
In the majority of production situations it is desirable to have a level of failover between the underlying datastores used for persistence. You have at least 2 options available to you here. These are shown below

Sequoia is a transparent middleware solution offering clustering, load balancing and failover services for any database. Sequoia is the continuation of the C-JDBC project. The database is distributed and replicated among several nodes and Sequoia balances the queries among these nodes. Sequoia handles node and network failures with transparent failover. It also provides support for hot recovery, online maintenance operations and online upgrades.
Sequoia can be used with DataNucleus by just providing the Sequoia datastore URLs as input to DataNucleus. There is a problem outstanding in Sequoia itself in that its JDBC driver doesnt provide DataNucleus with the correct major/minor versions of the underlying datastore. Until Sequoia fix this issue, use of Sequoia will be unreliable

DataNucleus has the capability to switch to between DataSources upon failure of one while obtaining a datastore connection. The failover mechanism is useful for applications with multiple database nodes when the data is actually replicated/synchronized by the underlying database. There are 2 things to be aware of before utilising this functionality.
Several failover algorithm are allowed to be used, one at time, as for example round-robin, ordered list or random. The default algorithm, ordered list, is described below and is provided by DataNucleus. You can also implement and plug your own algorithm. See Connection Provider.
To use failover, each datastore connection must be provided through DataSources. The datanucleus.ConnectionFactoryName property must be declared with a list of JNDI names pointing to DataSources, in the form of <JNDINAME> [,<JNDINAME>]. See the example:
datanucleus.ConnectionFactoryName=JNDINAME1,JNDINAME2
At least one least one JNDI name must be declared.
The Ordered List Algorithm (default) allows you to switch to slave DataSources upon failure of a master DataSource while obtaining a datastore connection. This is shown below.
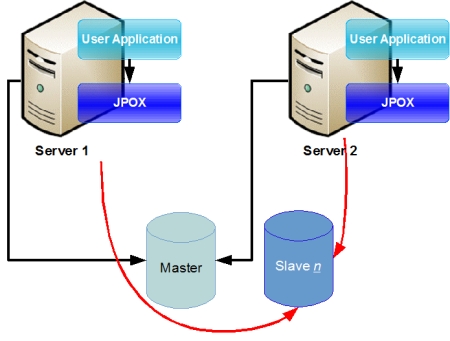
Each time DataNucleus needs to obtain a connection to the datastore, it takes the first DataSource, the Master, and tries, on failure to obtain the connection goes to the next on the list until it obtains a connection to the datastore or the end of the list is reached.
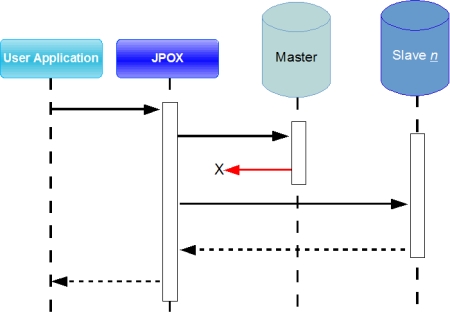
The first JNDI name in the datanucleus.ConnectionFactoryName property is the Master DataSource and the following JNDI names are the Slave DataSources.