
|

|

|

|

|

|

|
|
| DataNucleus AccessPlatform 4.1 Documentation |
|
|
|
|
|
|
|
|
|
|
You have a 1-N (one to many) when you have one object of a class that has a Collection of objects of another class. Please note that Collections allow duplicates, and so the persistence process reflects this with the choice of primary keys. There are two ways in which you can represent this in a datastore : Join Table (where a join table is used to provide the relationship mapping between the objects), and Foreign-Key (where a foreign key is placed in the table of the object contained in the Collection.
The various possible relationships are described below.
Please note that RDBMS supports the full range of options on this page, whereas other datastores (ODF, Excel, HBase, MongoDB, etc) persist the Collection in a column in the owner object rather than using join-tables or foreign-keys since those concepts are RDBMS-only
Important : The element of a Collection ought to define the methods equals and hashCode so that updates are detected correctly. This is because any Java Collection will use these to determine equality and whether an element is contained in the Collection. Note also that the hashCode() should be consistent throughout the lifetime of a persistable object. By that we mean that it should not use some basis before persistence and then use some other basis (such as the object identity) after persistence in the equals/hashCode methods.
We have 2 sample classes Account and Address. These are related in such a way as Account contains a Collection of objects of type Address, yet each Address knows nothing about the Account objects that it relates to. Like this
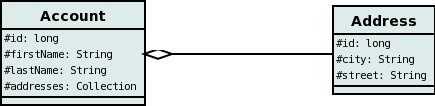
There are 2 ways that we can persist this relationship. These are shown below
If you define the XML metadata for these classes as follows
<entity-mappings>
<entity class="Account">
<table name="ACCOUNT"/>
<attributes>
<id name="id">
<column name="ACCOUNT_ID"/>
</id>
...
<one-to-many name="addresses" target-entity="com.mydomain.Address">
<join-table name="ACCOUNT_ADDRESSES">
<join-column name="ACCOUNT_ID_OID"/>
<inverse-join-column name="ADDRESS_ID_EID"/>
</join-table>
</one-to-many>
</attributes>
</entity>
<entity class="Address">
<table name="ADDRESS"/>
<attributes>
<id name="id">
<column name="ADDRESS_ID"/>
</id>
...
</attributes>
</entity>
</entity-mappings>or alternatively using annotations
public class Account
{
...
@OneToMany
@JoinTable(name="ACCOUNT_ADDRESSES",
joinColumns={@JoinColumn(name="ACCOUNT_ID_OID")},
inverseJoinColumns={@JoinColumn(name="ADDRESS_ID_EID")})
Collection<Address> addresses
}
public class Address
{
...
}| The crucial part is the join-table element on the field element - this signals to JPA to use a join table. |
This will create 3 tables in the database, one for Address, one for Account, and a join table, as shown below.

The join table is used to link the 2 classes via foreign keys to their primary key. This is useful where you want to retain the independence of one class from the other class.
If you wish to fully define the schema table and column names etc, follow these tips
In this relationship, the Account class has a List of Address objects, yet the Address knows nothing about the Account. In this case we don't have a field in the Address to link back to the Account and so DataNucleus has to use columns in the datastore representation of the Address class. So we define the XML metadata like this
<entity-mappings>
<entity class="Account">
<table name="ACCOUNT"/>
<attributes>
<id name="id">
<column name="ACCOUNT_ID"/>
</id>
...
<one-to-many name="addresses" target-entity="com.mydomain.Address">
<join-column name="ACCOUNT_ID"/>
</one-to-many>
</attributes>
</entity>
<entity class="Address">
<table name="ADDRESS"/>
<attributes>
<id name="id">
<column name="ADDRESS_ID"/>
</id>
...
</attributes>
</entity>
</entity-mappings>or alternatively using annotations
public class Account
{
...
@OneToMany
@JoinColumn(name="ACCOUNT_ID")
Collection<Address> addresses
}
public class Address
{
...
}Note that you MUST specify the join-column here otherwise it defaults to a join table with JPA!
There will be 2 tables, one for Address, and one for Account. If you wish to specify the names of the column(s) used in the schema for the foreign key in the Address table you should use the join-column element within the field of the collection.

In terms of operation within your classes of assigning the objects in the relationship. You have to take your Account object and add the Address to the Account collection field since the Address knows nothing about the Account.
If you wish to fully define the schema table and column names etc, follow these tips
Limitation : Since each Address object can have at most one owner (due to the "Foreign Key") this mode of persistence will not allow duplicate values in the Collection. If you want to allow duplicate Collection entries, then use the "Join Table" variant above.
We have 2 sample classes Account and Address. These are related in such a way as Account contains a Collection of objects of type Address, and each Address has a reference to the Account object that it relates to. Like this
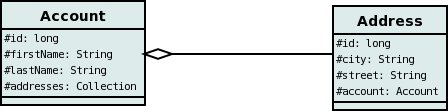
There are 2 ways that we can persist this relationship. These are shown below
If you define the XML metadata for these classes as follows
<entity-mappings>
<entity class="Account">
<table name="ACCOUNT"/>
<attributes>
<id name="id">
<column name="ACCOUNT_ID"/>
</id>
...
<one-to-many name="addresses" target-entity="com.mydomain.Address" mapped-by="account">
<join-table name="ACCOUNT_ADDRESSES">
<join-column name="ACCOUNT_ID_OID"/>
<inverse-join-column name="ADDRESS_ID_EID"/>
</join-table>
</one-to-many>
</attributes>
</entity>
<entity class="Address">
<table name="ADDRESS"/>
<attributes>
<id name="id">
<column name="ADDRESS_ID"/>
</id>
...
<many-to-one name="account"/>
</attributes>
</entity>
</entity-mappings>or alternatively using annotations
public class Account
{
...
@OneToMany(mappedBy="account")
@JoinTable(name="ACCOUNT_ADDRESSES",
joinColumns={@JoinColumn(name="ACCOUNT_ID_OID")},
inverseJoinColumns={@JoinColumn(name="ADDRESS_ID_EID")})
Collection<Address> addresses
}
public class Address
{
...
@ManyToOne
Account account;
...
}| The crucial part is the join element on the field element - this signals to JPA to use a join table. |
This will create 3 tables in the database, one for Address, one for Account, and a join table, as shown below.

The join table is used to link the 2 classes via foreign keys to their primary key. This is useful where you want to retain the independence of one class from the other class.
If you wish to fully define the schema table and column names etc, follow these tips
Here we have the 2 classes with both knowing about the relationship with the other.
If you define the XML metadata for these classes as follows
<entity-mappings>
<entity class="Account">
<table name="ACCOUNT"/>
<attributes>
<id name="id">
<column name="ACCOUNT_ID"/>
</id>
...
<one-to-many name="addresses" target-entity="com.mydomain.Address" mapped-by="account">
<join-column name="ACCOUNT_ID"/>
</one-to-many>
</attributes>
</entity>
<entity class="Address">
<table name="ADDRESS"/>
<attributes>
<id name="id">
<column name="ADDRESS_ID"/>
</id>
...
<many-to-one name="account"/>
</attributes>
</entity>
</entity-mappings>or alternatively using annotations
public class Account
{
...
@OneToMany(mappedBy="account")
@JoinColumn(name="ACCOUNT_ID")
Collection<Address> addresses
}
public class Address
{
...
@ManyToOne
Account account;
...
}| The crucial part is the mapped-by attribute of the field on the "1" side of the relationship. This tells the JPA implementation to look for a field called account on the Address class. |
This will create 2 tables in the database, one for Address (including an ACCOUNT_ID to link to the ACCOUNT table), and one for Account. Notice the subtle difference to this set-up to that of the Join Table relationship earlier.

If you wish to fully define the schema table and column names etc, follow these tips
Limitation : Since each Address object can have at most one owner (due to the "Foreign Key") this mode of persistence will not allow duplicate values in the Collection. If you want to allow duplicate Collection entries, then use the "Join Table" variant above.
In JPA1 you cannot have a 1-N collection of non-Entity objects. All of the examples above show a 1-N relationship between 2 persistable classes. If you want the element to be primitive or Object types then follow this section. For example, when you have a Collection of Strings. This will be persisted in the same way as the "Join Table" examples above. A join table is created to hold the collection elements. Let's take our example. We have an Account that stores a Collection of addresses. These addresses are simply Strings. We define the annotations like this
@Entity
public class Account
{
...
@ElementCollection
@CollectionTable(name="ACCOUNT_ADDRESSES")
Collection<String> addresses;
}or using XML metadata
<entity class="mydomain.Account">
<attributes>
...
<element-collection name="addresses">
<collection-table name="ACCOUNT_ADDRESSES"/>
</element-collection>
</attributes>
</entity>
In the datastore the following is created
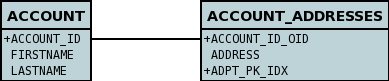
The ACCOUNT table is as before, but this time we only have the "join table". Use @Column on the field/method to define the column details of the element in the join table.
Just like in the above example, here we have a Collection of simple types. In this case we are wanting to store this Collection into a single column in the owning table. We do this by using a JPA AttributeConverter.
public class Account
{
...
@ElementCollection
@Convert(CollectionStringToStringConverter.class)
@Column(name="ADDRESSES")
Collection<String> addresses;
}and then define our converter. You can clearly define your conversion process how you want it. You could, for example, convert the Collection into comma-separated strings, or could use JSON, or XML, or some other format.
public class CollectionStringToStringConverter implements AttributeConverter<Collection<String>, String>
{
public String convertToDatabaseColumn(Collection<String> attribute)
{
if (attribute == null)
{
return null;
}
StringBuilder str = new StringBuilder();
... convert Collection to String
return str.toString();
}
public Collection<String> convertToEntityAttribute(String columnValue)
{
if (columnValue == null)
{
return null;
}
Collection<String> coll = new HashSet<String>();
... convert String to Collection
return coll;
}
}
The relationships using join tables shown above rely on the join table relating to the relation in question. DataNucleus allows the possibility of sharing a join table between relations. The example below demonstrates this. We take the example as show above (1-N Unidirectional Join table relation), and extend Account to have 2 collections of Address records. One for home addresses and one for work addresses, like this

We now change the metadata we had earlier to allow for 2 collections, but sharing the join table
<entity-mappings>
<entity class="Account">
<table name="ACCOUNT"/>
<attributes>
<id name="id">
<column name="ACCOUNT_ID"/>
</id>
...
<one-to-many name="workAddresses" target-entity="com.mydomain.Address">
<join-table name="ACCOUNT_ADDRESSES">
<join-column name="ACCOUNT_ID_OID"/>
<inverse-join-column name="ADDRESS_ID_EID"/>
</join-table>
<extension key="relation-discriminator-column" value="ADDRESS_TYPE"/>
<extension key="relation-discriminator-pk" value="true"/>
<extension key="relation-discriminator-value" value="work"/>
</one-to-many>
<one-to-many name="homeAddresses" target-entity="com.mydomain.Address">
<join-table name="ACCOUNT_ADDRESSES">
<join-column name="ACCOUNT_ID_OID"/>
<inverse-join-column name="ADDRESS_ID_EID"/>
</join-table>
<extension key="relation-discriminator-column" value="ADDRESS_TYPE"/>
<extension key="relation-discriminator-pk" value="true"/>
<extension key="relation-discriminator-value" value="home"/>
</one-to-many>
</attributes>
</entity>
<entity class="Address">
<table name="ADDRESS"/>
<attributes>
<id name="id">
<column name="ADDRESS_ID"/>
</id>
...
</attributes>
</entity>
</entity-mappings>or with annotations
public class Account
{
...
@OneToMany
@JoinTable(name="ACCOUNT_ADDRESSES",
joinColumns={@JoinColumn(name="ACCOUNT_ID_OID")},
inverseJoinColumns={@JoinColumn(name="ADDRESS_ID_EID")})
@Extensions({@Extension(key="relation-discriminator-column", value="ADDRESS_TYPE"),
@Extension(key="relation-discriminator-pk", value="true"),
@Extension(key="relation-discriminator-value", value="work")}
Collection<Address> workAddresses;
@OneToMany
@JoinTable(name="ACCOUNT_ADDRESSES",
joinColumns={@JoinColumn(name="ACCOUNT_ID_OID")},
inverseJoinColumns={@JoinColumn(name="ADDRESS_ID_EID")})
@Extensions({@Extension(key="relation-discriminator-column", value="ADDRESS_TYPE"),
@Extension(key="relation-discriminator-pk", value="true"),
@Extension(key="relation-discriminator-value", value="home")}
Collection<Address> homeAddresses;
...
}So we have defined the same join table for the 2 collections "ACCOUNT_ADDRESSES", and the same columns in the join table, meaning that we will be sharing the same join table to represent both relations. The important step is then to define the 3 DataNucleus extension tags. These define a column in the join table (the same for both relations), and the value that will be populated when a row of that collection is inserted into the join table. In our case, all "home" addresses will have a value of "home" inserted into this column, and all "work" addresses will have "work" inserted. This means we can now identify easily which join table entry represents which relation field.
This results in the following database schema

The relationships using foreign keys shown above rely on the foreign key relating to the relation in question. DataNucleus allows the possibility of sharing a foreign key between relations between the same classes. The example below demonstrates this. We take the example as show above (1-N Unidirectional Foreign Key relation), and extend Account to have 2 collections of Address records. One for home addresses and one for work addresses, like this

We now change the metadata we had earlier to allow for 2 collections, but sharing the join table
<entity-mappings>
<entity class="Account">
<table name="ACCOUNT"/>
<attributes>
<id name="id">
<column name="ACCOUNT_ID"/>
</id>
...
<one-to-many name="workAddresses" target-entity="com.mydomain.Address">
<join-column name="ACCOUNT_ID_OID"/>
<extension key="relation-discriminator-column" value="ADDRESS_TYPE"/>
<extension key="relation-discriminator-value" value="work"/>
</one-to-many>
<one-to-many name="homeAddresses" target-entity="com.mydomain.Address">
<join-column name="ACCOUNT_ID_OID"/>
<extension key="relation-discriminator-column" value="ADDRESS_TYPE"/>
<extension key="relation-discriminator-value" value="home"/>
</one-to-many>
</attributes>
</entity>
<entity class="Address">
<table name="ADDRESS"/>
<attributes>
<id name="id">
<column name="ADDRESS_ID"/>
</id>
...
</attributes>
</entity>
</entity-mappings>or with annotations
public class Account
{
...
@OneToMany
@Extensions({@Extension(key="relation-discriminator-column", value="ADDRESS_TYPE"),
@Extension(key="relation-discriminator-value", value="work")}
Collection<Address> workAddresses;
@OneToMany
@Extensions({@Extension(key="relation-discriminator-column", value="ADDRESS_TYPE"),
@Extension(key="relation-discriminator-value", value="home")}
Collection<Address> homeAddresses;
...
}So we have defined the same foreign key for the 2 collections "ACCOUNT_ID_OID", The important step is then to define the 2 DataNucleus extension tags. These define a column in the element table (the same for both relations), and the value that will be populated when a row of that collection is inserted into the element table. In our case, all "home" addresses will have a value of "home" inserted into this column, and all "work" addresses will have "work" inserted. This means we can now identify easily which element table entry represents which relation field.
This results in the following database schema
